[Series] Database Internals - Bài 1: Tại sao RDBMS lưu dữ liệu khác với File thông thường?
![[Series] Database Internals - Bài 1: Tại sao RDBMS lưu dữ liệu khác với File thông thường?](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.5746714924169717.png&w=3840&q=75)
Dữ liệu trong Database không nằm im lìm như những dòng chữ trong một file văn bản thông thường. Phía sau mỗi câu lệnh SQL là một hệ thống phân tầng phức tạp, nơi dữ liệu được đóng gói vào các "thùng hàng" (Page), vận chuyển qua lại giữa RAM và Disk, rồi được sắp xếp theo những quy luật khắt khe để chiến thắng rào cản tốc độ của ổ cứng.
Series "Database Internals" này được mình viết ra với mục tiêu giúp bạn nhìn xuyên thấu lớp vỏ SQL, mở nắp chiếc "hộp đen" DBMS để hiểu về những bánh răng đang vận hành bền bỉ bên dưới. Chúng ta sẽ cùng khám phá từ những đơn vị lưu trữ nhỏ nhất như Slotted Page cho đến những cấu trúc vĩ đại như B-Tree hay LSM-Tree. Nếu bạn từng thắc mắc điều gì tạo nên tốc độ thần sầu của Database, thì đây chính là hành trình dành cho bạn.
1. Mở đầu: Lầm tưởng về "File văn bản khổng lồ"
Khi mới bắt đầu tiếp cận với lập trình, nhiều người trong chúng ta thường mường tượng Database giống như một file .txt hoặc .csv cực kỳ lớn được lưu trên ổ đĩa. Trong kịch bản đó, câu lệnh SQL chỉ đóng vai trò như một bộ lọc (filter) để duyệt từ đầu đến cuối file nhằm tìm ra dòng dữ liệu cần thiết.
Tuy nhiên, thực tế lại khác xa như vậy. Hãy thử làm một bài toán nhỏ:
Nếu bạn có một file log nặng vài GB và mở nó bằng Notepad, máy tính của bạn gần như chắc chắn sẽ "treo cứng" vì hệ thống phải nỗ lực nạp toàn bộ nội dung vào bộ nhớ.
Thế nhưng, cũng với lượng dữ liệu đó, một hệ quản trị cơ sở dữ liệu (DBMS) có thể xử lý hàng ngàn truy vấn cùng lúc và trả về kết quả chỉ trong vài mili giây.
Tại sao lại có sự chênh lệch khủng khiếp này?

Câu trả lời nằm ở chỗ: Database không bao giờ lưu dữ liệu một cách "phẳng" và thô sơ. Nếu lưu dưới dạng file văn bản, mỗi lần bạn muốn tìm kiếm hay cập nhật một bản ghi, hệ thống sẽ phải quét qua toàn bộ dữ liệu (Full Scan), gây ra một lượng Disk I/O (đọc/ghi ổ đĩa) khổng lồ. Trong khi đó, ổ cứng chính là linh kiện chậm chạp nhất trong hệ thống máy tính.
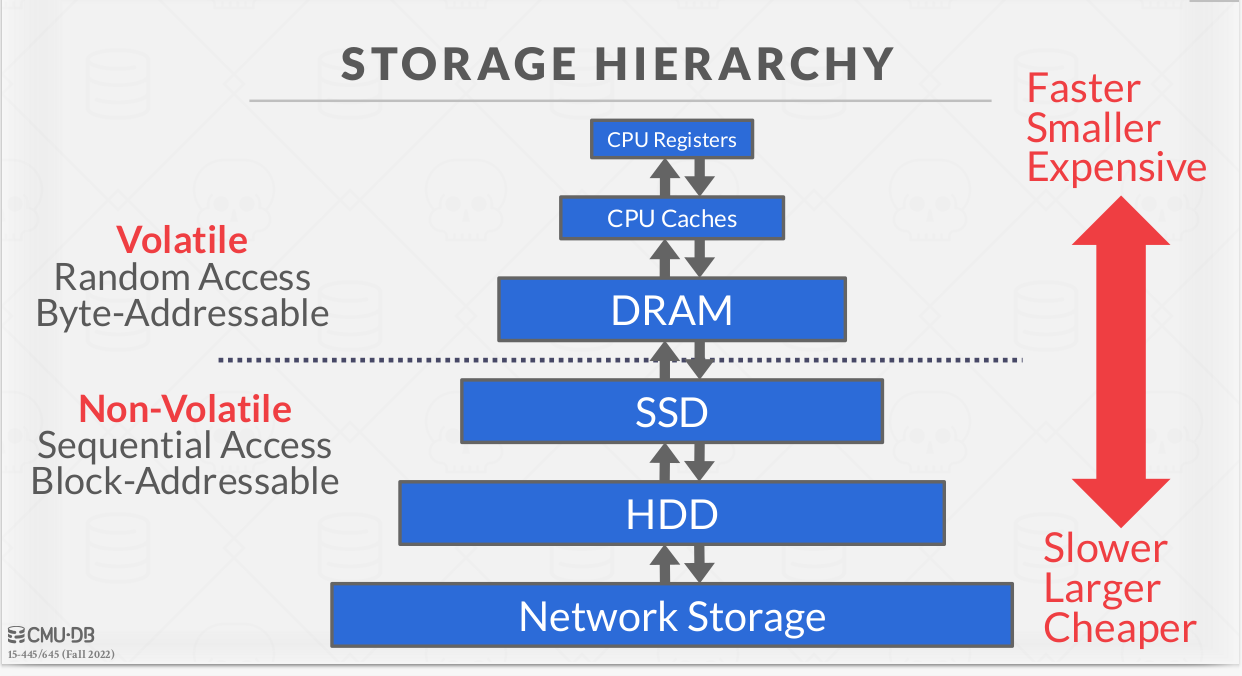
Để giải quyết bài toán này, DBMS đã "phức tạp hóa" cách lưu trữ ngay từ tầng thấp nhất. Nó chia nhỏ dữ liệu thành các khối cố định gọi là Page, xây dựng các tầng quản lý bộ nhớ đệm (Buffer Pool) và thiết lập các "bản đồ" tìm kiếm (Index). Thay vì đọc cả một file khổng lồ, Database chỉ cần "bốc" đúng những mảnh dữ liệu nhỏ cần thiết lên RAM để xử lý.
2. Trận chiến tốc độ: RAM vs. Disk
Để hiểu tại sao Database phải "phức tạp hóa" cách lưu trữ, chúng ta cần nhìn vào sự thật phũ phàng về phần cứng: Sự chênh lệch tốc độ khủng khiếp giữa RAM và Ổ cứng (Disk).
Trong kiến trúc máy tính, RAM (Bộ nhớ trong) giống như bàn làm việc của bạn — rất nhanh, nhưng không gian có hạn và dữ liệu sẽ mất sạch khi ngắt điện. Ngược lại, Ổ cứng (HDD/SSD) giống như một cái kho chứa khổng lồ — lưu trữ bền bỉ theo năm tháng nhưng tốc độ truy cập lại cực kỳ chậm chạp.
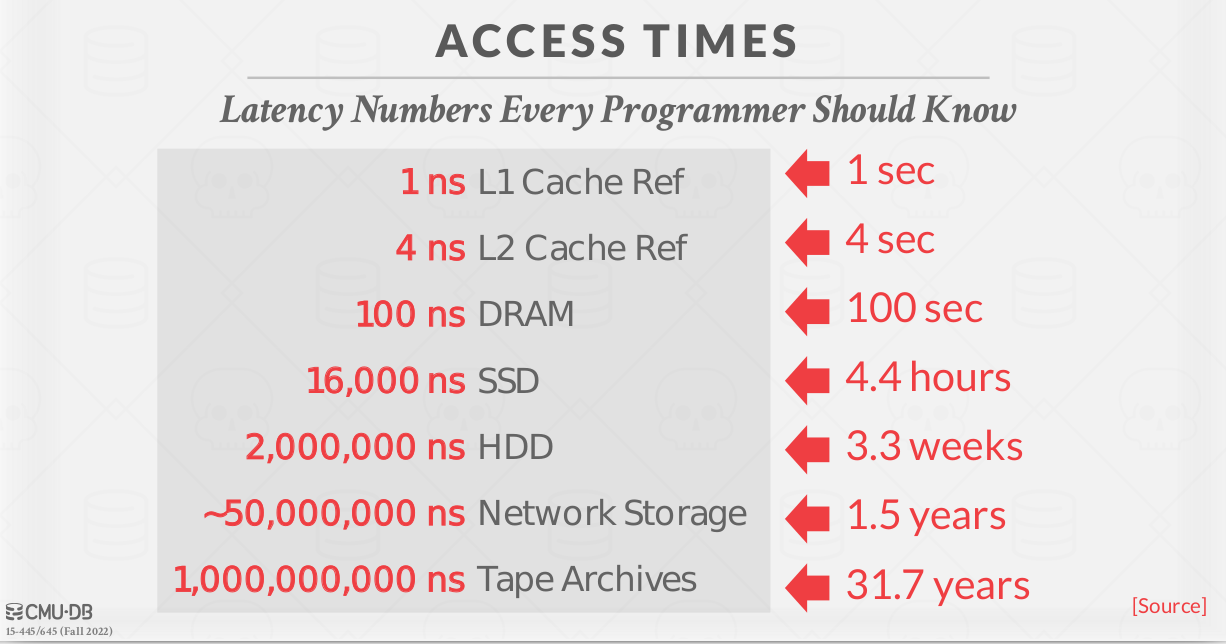
Khái niệm Disk I/O: "Ông thủ thư đi bộ"
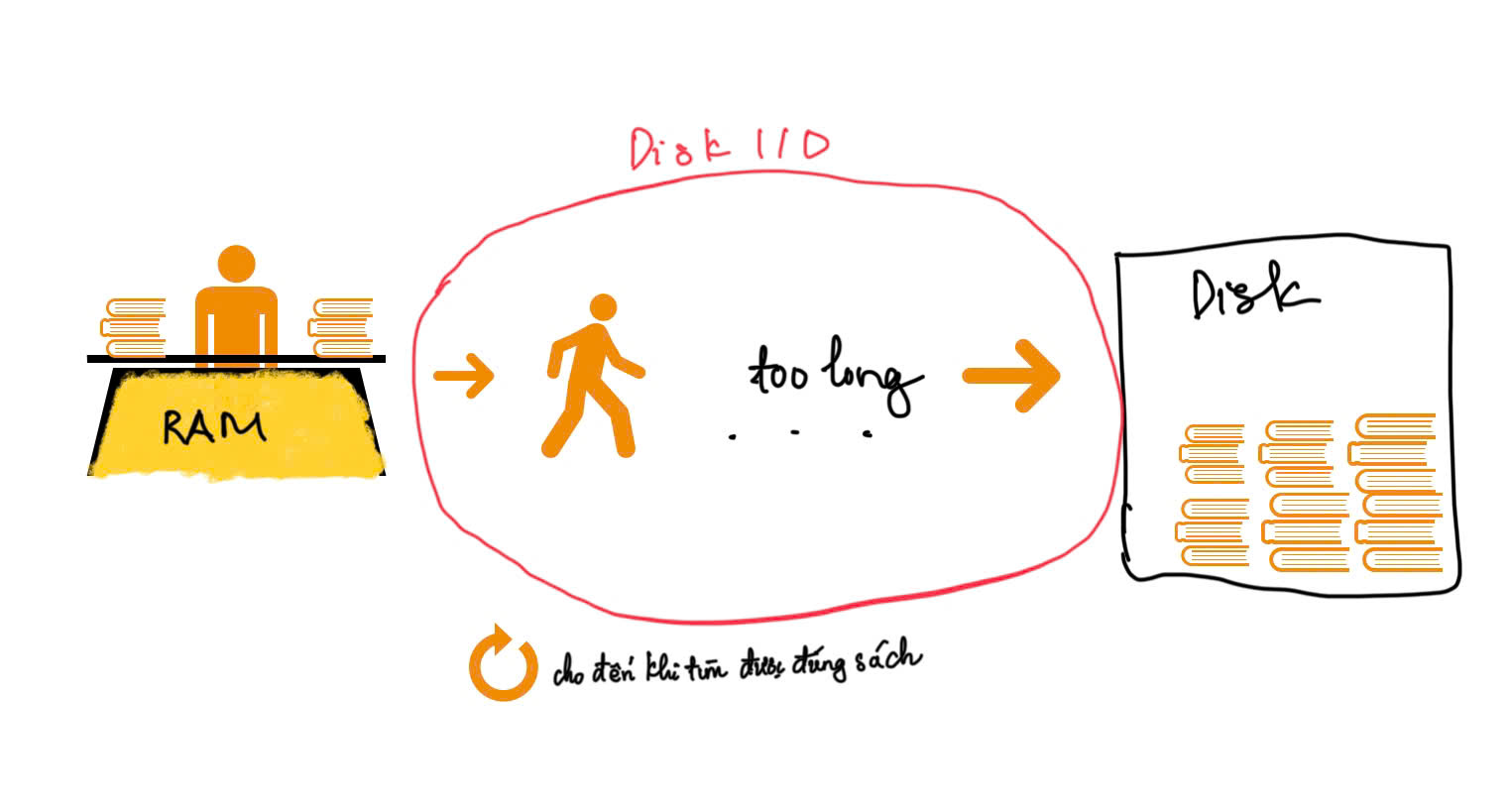
Mỗi khi chương trình của bạn cần lấy một dữ liệu không có sẵn trong RAM, hệ thống phải thực hiện một thao tác gọi là Disk I/O (Đọc/Ghi dữ liệu từ ổ đĩa).
Hãy tưởng tượng bạn là một kỹ sư đang ngồi tại bàn làm việc (RAM). Mỗi lần bạn cần một thông tin từ Database, bạn phải nhờ "Ông thủ thư" (Hệ điều hành/Phần cứng) đi bộ xuống kho ở tầng hầm (Disk) để lấy sách.
Thao tác trên RAM chỉ mất vài nanomet (giống như bạn với tay lấy tài liệu ngay trên bàn).
Thao tác trên Disk có thể mất vài mili giây (giống như ông thủ thư phải đi bộ mất 10 phút).
Trong thế giới của những hệ thống xử lý hàng triệu bản ghi, việc "đi bộ" này chính là botttleneck lớn nhất. Nếu Database không có một chiến lược quản lý thông minh, toàn bộ ứng dụng của bạn sẽ phải đứng đợi ông thủ thư "đi bộ" liên tục.
Mục tiêu lớn nhất của mọi DBMS: Giảm tối đa Disk I/O
Mọi cấu trúc phức tạp mà chúng ta sẽ tìm hiểu trong series này — từ Page, Buffer Pool cho đến B-Tree — thực chất đều phục vụ một mục đích duy nhất: Làm sao để ông thủ thư ít phải đi bộ nhất có thể.
Database giải quyết vấn đề này bằng hai chiến thuật chính:
Gom nhóm dữ liệu: Thay vì đi lấy từng mẩu tin nhỏ lẻ, Database sẽ bê nguyên một "thùng sách" (Page) lên bàn làm việc để dùng dần.
Sử dụng bản đồ: Thay vì lục tung cả kho, Database sử dụng các "tấm bản đồ" (Index) để chỉ đích danh thùng sách đó nằm ở đâu, giúp ông thủ thư đi thẳng tới đích mà không tốn công tìm kiếm.
3. Page – Đơn vị vận chuyển "thông minh"
Nếu ở mục trước, chúng ta ví Disk I/O là việc "đi bộ xuống kho", thì câu hỏi đặt ra là: Khi xuống tới kho rồi, ông thủ thư sẽ mang cái gì lên?
Trong một file văn bản bình thường, dữ liệu là một dòng chảy liên tục không có điểm dừng. Nhưng trong Database, dữ liệu được chia nhỏ thành những khối có kích thước cố định, gọi là Page (Trang dữ liệu). Đây chính là đơn vị nhỏ nhất mà Database sử dụng để trao đổi dữ liệu giữa Ổ cứng và RAM.
Tại sao lại là Page mà không phải từng dòng dữ liệu?
Hãy tưởng tượng bạn cần tìm tên của một người trong một cuốn từ điển khổng lồ. Thay vì xé đúng một mẩu giấy nhỏ chứa cái tên đó, bạn sẽ lật cả một trang sách (Page) để đọc. Tại sao?
Chi phí vận chuyển: Việc bốc 1 byte hay bốc 16KB dữ liệu từ ổ đĩa tốn thời gian gần như tương đương nhau do cơ chế vật lý của đầu đọc. Vậy nên, Database chọn cách "bê nguyên thùng" cho bõ công đi lại.
Tính cục bộ (Locality): Theo kinh nghiệm thực tế, nếu bạn vừa truy cập vào bản ghi của khách hàng A, rất có thể ngay sau đó bạn sẽ cần xem đơn hàng của họ hoặc thông tin của khách hàng B nằm ngay kế bên. Bằng cách bê cả Page 16KB chứa nhiều bản ghi, Database tăng tỉ lệ "đánh trúng" dữ liệu trong RAM cho những lần truy vấn tiếp theo.
"Thùng hàng" Page có gì bên trong?
Kích thước Page phổ biến nhất hiện nay là 8KB (PostgreSQL) hoặc 16KB (MySQL InnoDB). Dù nhỏ bé, nhưng mỗi Page lại là một "thành phố" thu nhỏ với cấu trúc cực kỳ quy củ:
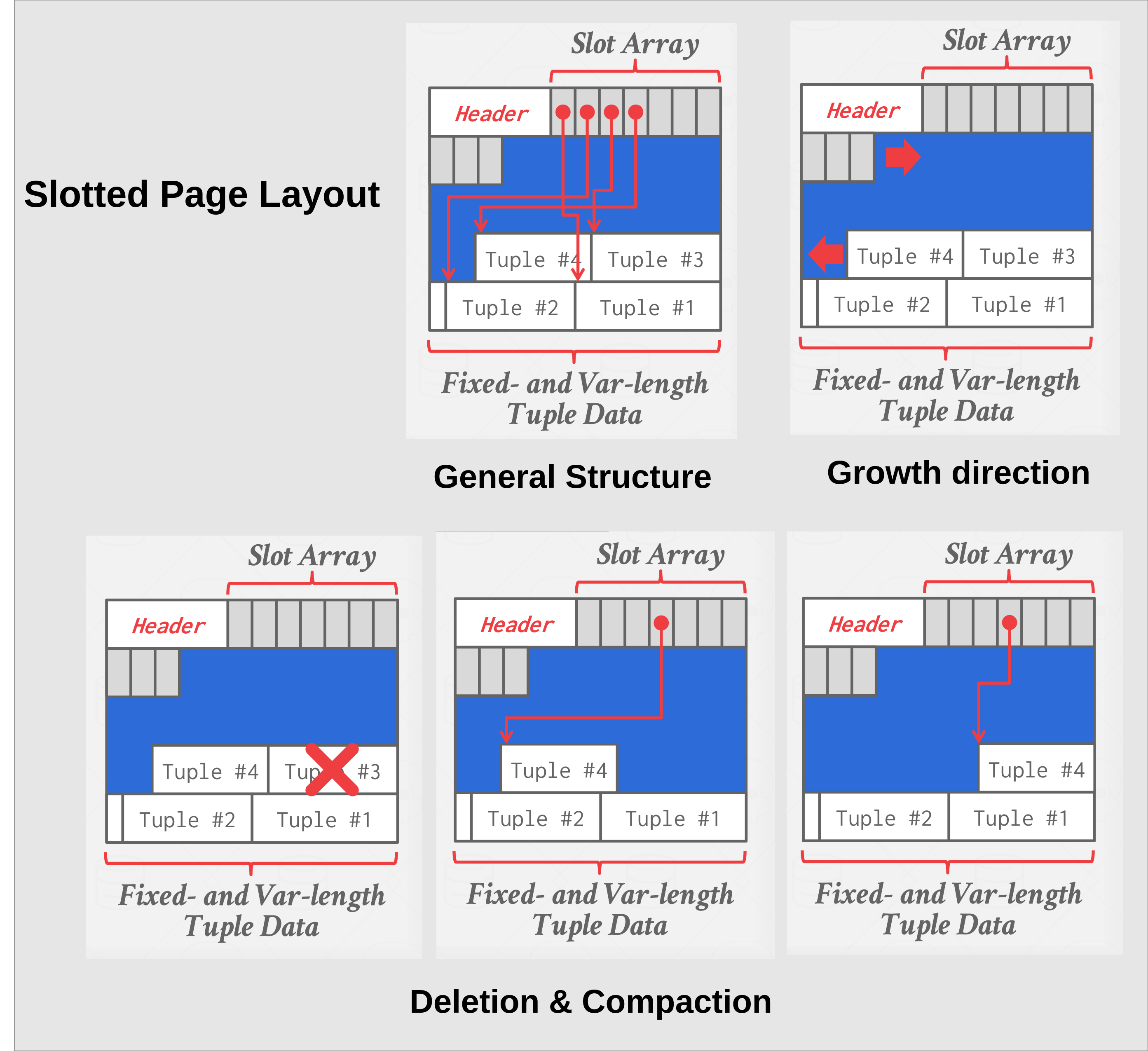
Header: Chứa các thông tin metadata như Page ID, kích thước còn trống, và vị trí các bản ghi.
Dữ liệu thực tế (Tuples): Nơi lưu trữ các dòng dữ liệu mà bạn Insert vào.
Slot Array: Một mảng các con trỏ đóng vai trò như "bản đồ nội bộ" của Page, giúp chúng ta tìm thấy dữ liệu ngay cả khi chúng bị xáo trộn vị trí bên trong thùng.
Tầm quan trọng của Page đối với Developer
Hiểu về Page giúp bạn giải mã được nhiều bí ẩn trong quá trình coding. Ví dụ, tại sao việc SELECT * lại gây tốn tài nguyên? Bởi vì dù bạn chỉ cần 1 cột, Database vẫn phải bốc nguyên một "thùng hàng" 16KB chứa tất cả các cột của bản ghi đó lên RAM. Nếu bản ghi quá lớn, số lượng Page cần đọc tăng lên, đồng nghĩa với việc "ông thủ thư" phải đi bộ nhiều hơn, làm chậm ứng dụng của bạn.
4. Bức tranh toàn cảnh: Các tầng xử lý của RDBMS
Sau khi đã hiểu về Page — những "thùng hàng" chứa dữ liệu — câu hỏi tiếp theo là: Ai là người quản lý, vận chuyển và ra lệnh khai thác những thùng hàng này?
Dựa trên sơ đồ kiến trúc kinh điển của một RDBMS, chúng ta có thể chia bộ máy này thành các tầng chuyên biệt, hoạt động nhịp nhàng từ thấp lên cao:

Tầng Disk Manager (Quản lý ổ đĩa)
Đây là tầng thấp nhất, làm việc trực tiếp với phần cứng. Nhiệm vụ của nó là quản lý các file trên đĩa cứng và tổ chức chúng thành các Page. Disk Manager không quan tâm bên trong Page chứa tên khách hàng hay số điện thoại; nó chỉ quan tâm việc ghi dữ liệu vào đúng vị trí vật lý và đọc chúng ra khi có yêu cầu.
Tầng Buffer Pool Manager (Quản lý bộ nhớ đệm)
Đây chính là "trạm trung chuyển" giữa Disk chậm chạp và RAM tốc độ cao.
Khi hệ thống cần một Page, tầng này sẽ kiểm tra xem Page đó đã có trên RAM chưa.
Nếu chưa, nó sẽ ra lệnh cho Disk Manager "bốc" Page đó lên.
Nếu RAM đã đầy, nó sẽ quyết định xem nên đẩy Page nào ít dùng nhất về lại ổ đĩa để nhường chỗ. Đây là tầng cực kỳ quan trọng giúp giảm thiểu việc "đi bộ" (Disk I/O) mà chúng ta đã thảo luận.
Tầng Access Methods (Phương thức truy cập)
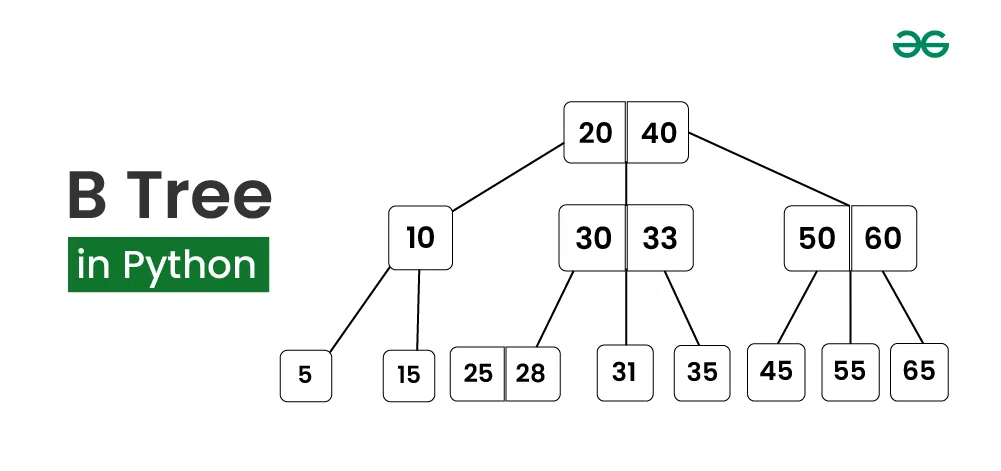
Đây là nơi chứa các cấu trúc dữ liệu "thần thánh" như B-Tree hay LSM Tree. Tầng này sử dụng các Page từ Buffer Pool để xây dựng nên những tấm bản đồ dẫn đường. Thay vì đọc mọi Page, nó sẽ chỉ dẫn: "Dữ liệu bạn cần nằm ở Page số 10, Slot số 3".
Tầng Query Planning & Execution (Não bộ hệ thống)
Đây là tầng cao nhất, nơi tiếp nhận câu lệnh SQL từ bạn. Nó sẽ phân tích câu lệnh, lập ra một kế hoạch thực thi tối ưu nhất (ví dụ: nên dùng Index nào) và ra lệnh cho tầng Access Methods đi lấy dữ liệu.
Tạm kết bài 1: Sự phối hợp hoàn hảo
Bạn có thể thấy, để trả về kết quả cho một câu
SELECTđơn giản, Database đã phải huy động một bộ máy phân tầng cực kỳ chặt chẽ:
Query Planning vạch ra lộ trình.
Access Methods tra cứu bản đồ.
Buffer Pool kiểm tra bàn làm việc (RAM).
Disk Manager (nếu cần) sẽ chạy xuống kho (Disk) để lấy hàng.
Việc hiểu được bức tranh tổng quan này là nền tảng để bạn không còn coi Database là một "hộp đen". Trong các bài viết tiếp theo trên phucbui2it, chúng ta sẽ bắt đầu "mổ xẻ" sâu hơn vào cấu trúc vi mô bên trong mỗi Page và cách các tầng này thực sự "nói chuyện" với nhau.


![[Series] Database Internals - Bài 2: Giải mã "Thùng sách" – Nghệ thuật sắp xếp Slotted Page Layout](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.30555181914624063.png&w=3840&q=75)