LSM-Tree – Cơ Chế Lưu Trữ Đằng Sau Sức Mạnh Ghi Dữ Liệu Của NoSQL

Trong thế giới Database, nếu B-Tree là một thủ thư cần mẫn luôn sắp xếp mọi cuốn sách vào đúng vị trí ngay khi chúng vừa cập bến, thì LSM-Tree (Log-Structured Merge-Tree) lại chọn một lối sống khác: Sự lười biếng có tính toán. Thay vì tốn sức sắp xếp dữ liệu ngay lập tức trên đĩa, LSM-Tree trì hoãn việc đó, biến những thao tác ghi ngẫu nhiên (Random I/O) chậm chạp thành những dòng dữ liệu tuần tự (Sequential I/O) thần tốc.
1. Bản Chất Của "Sự Lười Biếng": Tại Sao Ghi Tuần Tự Lại Thắng?
Để hiểu tại sao LSM-Tree lại "lười", chúng ta cần nhìn vào giới hạn vật lý của thiết bị lưu trữ. Với HDD, việc di chuyển đầu đọc (Seek time) và chờ đĩa quay (Rotation time) khiến tốc độ ghi ngẫu nhiên cực kỳ thấp. Công thức tính hiệu suất I/O minh chứng cho điều này:
$$IOPS = \frac{1}{\text{seek time} + \text{rotation time}}$$
Trong khi B-Tree cố gắng cập nhật dữ liệu tại chỗ (In-place update)—buộc đầu đọc phải nhảy liên tục trên các Page khác nhau—thì LSM-Tree chọn cách Append-only. Nó chỉ đơn giản là viết tiếp vào cuối, tận dụng tối đa băng thông của ghi tuần tự.
2. Quy Trình Vận Hành: Ba Tầng Của Một "Kẻ Lười Biếng"
Sự lười biếng của LSM-Tree không đồng nghĩa với sự hỗn loạn. Nó được tổ chức cực kỳ khoa học qua 3 giai đoạn:
A. Tầng 1: Ghi vào sổ tay tạm thời (Memtable & WAL)
Write-Ahead Log (WAL): Trước khi làm bất cứ việc gì, "kẻ lười" sẽ ghi nhanh yêu cầu vào một file nhật ký (WAL) trên đĩa để đảm bảo tính Durability. Nếu hệ thống sập, dữ liệu sẽ không bị mất.
Memtable: Dữ liệu sau đó được đưa vào RAM, trong một cấu trúc gọi là Memtable (thường là Red-Black Tree hoặc Skip List). Ở đây, dữ liệu được sắp xếp theo khóa ($Key$) một cách cực nhanh vì nó diễn ra trong bộ nhớ.
B. Tầng 2: Đóng gói và lưu kho (SSTable)
Khi Memtable đầy, nó không đi tìm dữ liệu cũ để ghi đè. Thay vào đó, nó đóng gói toàn bộ nội dung thành một file gọi là SSTable (Sorted String Table) và đẩy xuống đĩa.
Immutable: Một khi SSTable đã ghi xuống đĩa, nó là bất biến.
Sequential Access: Vì dữ liệu đã được sắp xếp trong RAM trước khi ghi, nên quá trình "flush" này diễn ra tuần tự, giúp inserts cực kỳ nhanh.
C. Tầng 3: Ngày dọn dẹp (Compaction)
Vì "lười" sắp xếp ngay từ đầu, dữ liệu về một đối tượng có thể nằm rải rác ở nhiều file SSTable khác nhau. Do đó, định kỳ hệ thống sẽ thực hiện Compaction—quá trình gộp các file SSTable, loại bỏ dữ liệu cũ và các Tombstones (đánh dấu dữ liệu đã xóa).
3. Nghệ Thuật Tìm Kiếm Trong "Đống Đồ Lộn Xộn"
Nhược điểm của việc lười sắp xếp là khi cần đọc, bạn có thể phải tìm ở nhiều nơi (Read Amplification). Để khắc phục, LSM-Tree sử dụng hai kỹ thuật thông minh:
Summary Tables: Lưu trữ dải khóa ($Min$ - $Max$) của mỗi SSTable để loại biên các file không liên quan.
Bloom Filters: Một bộ lọc xác suất nằm trên RAM. Nó giúp hệ thống trả lời ngay lập tức nếu một khóa chắc chắn không tồn tại trong một file, giúp tránh lãng phí Disk I/O vô ích.
4. Chiến Lược Dọn Dẹp (Compaction Strategies)
LSM-Tree cung cấp hai lựa chọn đánh đổi tùy theo mục đích sử dụng:
Leveled Compaction: 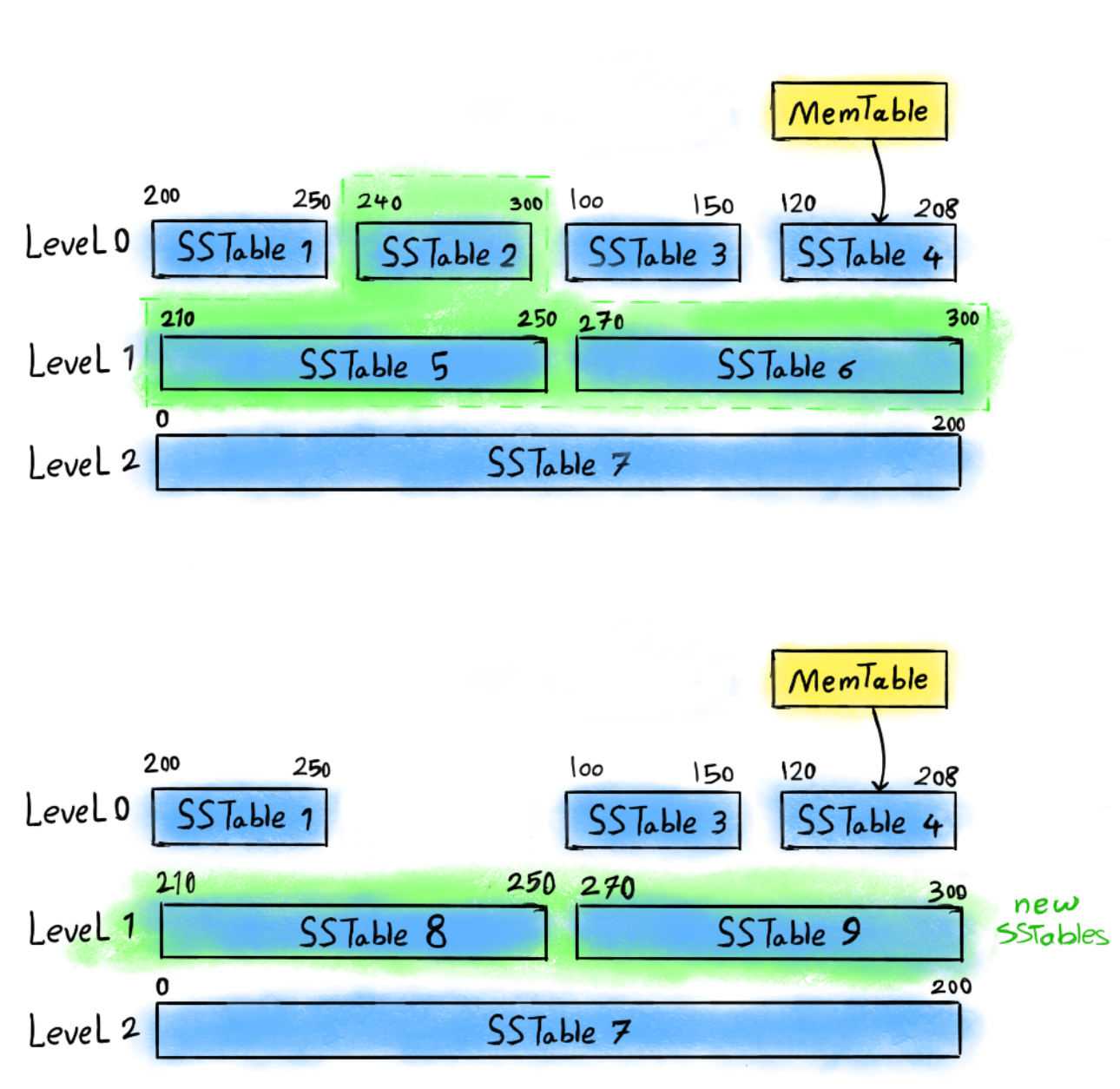
Tired Compaction: 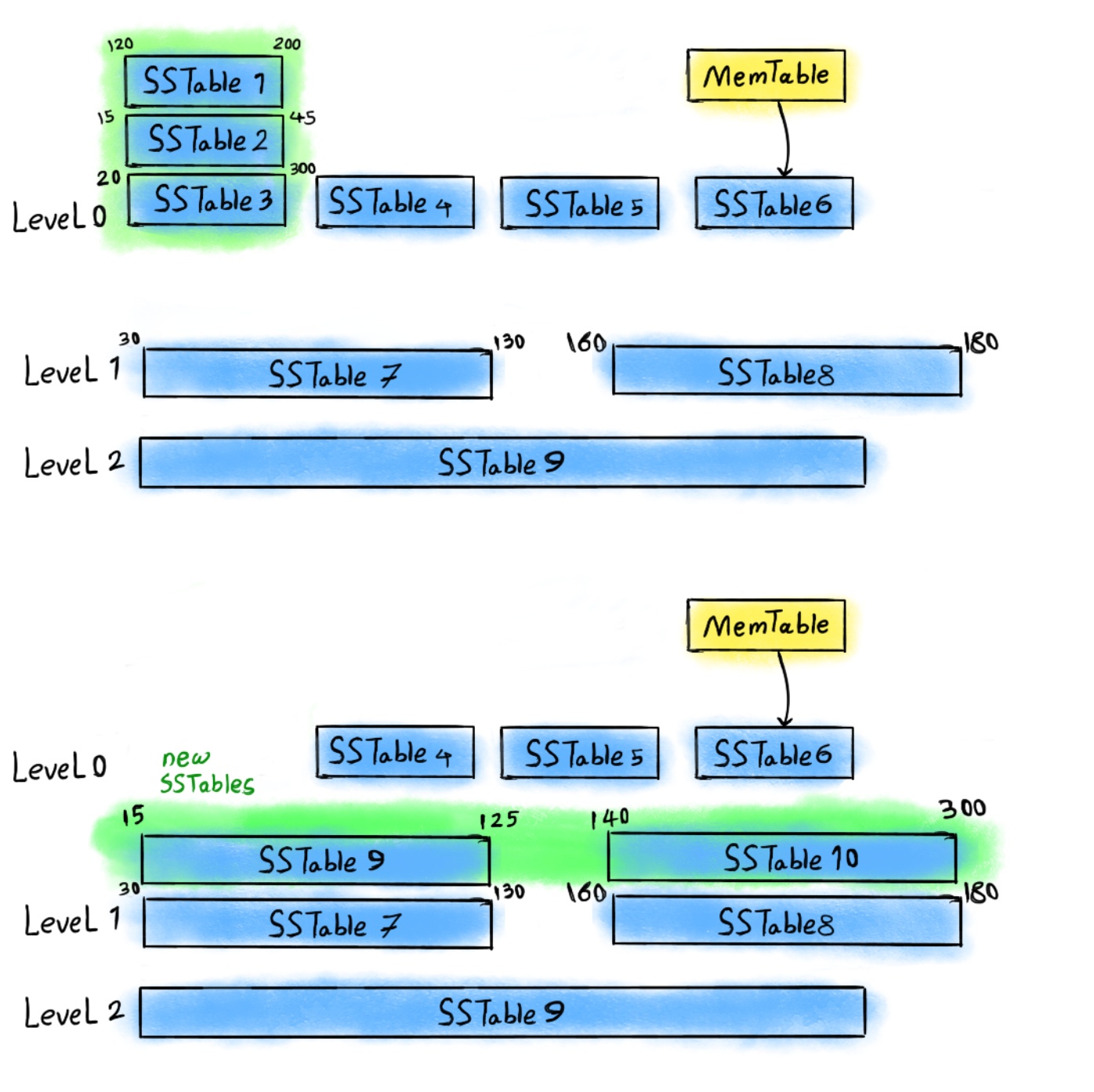
Chiến lược | Đặc điểm | Ưu điểm | Nhược điểm |
Leveled Compaction | Chia dữ liệu thành nhiều tầng ($L_0, L_1, L_2$). File tầng trên gộp với tầng dưới theo dải khóa. | Đọc rất nhanh, tiết kiệm không gian (Space amplification thấp). | Write Amplification cao do phải chép đi chép lại nhiều lần khi merge. |
Tiered Compaction | Gom các file có kích thước tương đương thành một file lớn hơn. | Tốc độ ghi cực cao, phù hợp với các hệ thống ghi liên tục. | Đọc chậm hơn vì một khóa có thể nằm ở nhiều file cùng tầng. |
5. Kết Luận: Khi Nào Nên Chọn Sự "Lười Biếng"?
LSM-Tree là minh chứng cho việc trì hoãn một cách thông minh có thể mang lại hiệu suất vượt trội. Trong khi B-Tree vẫn là "Vua" của những hệ thống đòi hỏi tính nhất quán ACID chặt chẽ và truy vấn đọc nhanh, thì LSM-Tree lại là "Quái vật" trong các hệ thống NoSQL (như Cassandra, RocksDB) xử lý hàng tỷ bản ghi mỗi giây.
Sự lựa chọn giữa B-Tree và LSM-Tree thực chất là sự đánh đổi giữa Read Performance và Write Performance.

![[Series] Database Internals - Bài 1: Tại sao RDBMS lưu dữ liệu khác với File thông thường?](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.5746714924169717.png&w=3840&q=75)
![[Series] Database Internals - Bài 2: Giải mã "Thùng sách" – Nghệ thuật sắp xếp Slotted Page Layout](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.30555181914624063.png&w=3840&q=75)