[Series] Database Internals - Bài 2: Giải mã "Thùng sách" – Nghệ thuật sắp xếp Slotted Page Layout
![[Series] Database Internals - Bài 2: Giải mã "Thùng sách" – Nghệ thuật sắp xếp Slotted Page Layout](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.30555181914624063.png&w=3840&q=75)
Chào các bạn, mình là Phúc.
Ở bài trước, chúng ta đã biết Database vận chuyển dữ liệu theo từng khối gọi là Page để tối ưu Disk I/O. Nhưng có bao giờ bạn tự hỏi: "Bên trong cái túi 8KB hay 16KB đó, các dòng dữ liệu (Rows) được xếp như thế nào? Phải chăng cứ ném bừa vào là xong?"
Câu trả lời là: Không. Nếu xếp bừa bãi, việc tìm kiếm và cập nhật sẽ trở thành một thảm họa. Đó là lý do Slotted Page Layout ra đời – một "di sản" thiết kế cực kỳ thông minh mà bạn sẽ thấy trong hầu hết các RDBMS hiện đại.
1. Tại sao không xếp dữ liệu nối đuôi nhau?
Thông thường, chúng ta nghĩ cứ viết bản ghi số 1, rồi đến số 2 ngay sát nút là xong. Nhưng đời không như là mơ:
Khi bạn Xóa (Delete): Một khoảng trống xuất hiện ở giữa. Nếu không lấp đầy, Page sẽ bị "thủng lỗ chỗ" (Fragmentation).
Khi bạn Cập nhật (Update): Bản ghi số 1 bỗng nhiên dài ra (ví dụ từ
VARCHAR(10)lênVARCHAR(100)), nó sẽ lấn chiếm chỗ của bản ghi số 2.
Để giải quyết việc "nhảy múa" này mà không làm hỏng địa chỉ tìm kiếm, Database sử dụng cấu trúc Slotted Page.
2. Cấu trúc của một Slotted Page
Như đã đề cập, một Page (thường là 8KB hoặc 16KB) không phải là một khối dữ liệu đặc mà là một cấu trúc được phân lớp cực kỳ khoa học. Hãy tưởng tượng Page như một kho chứa đồ thông minh có hai cửa: Cửa Header ở phía trên và Cửa Data ở phía dưới.
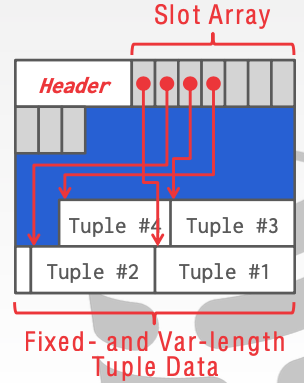
2.1. Page Header: Bộ não điều khiển
Nằm ở những byte đầu tiên của Page, Header chứa các thông tin metadata cực kỳ quan trọng giúp DBMS biết cách xử lý trang đó mà không cần đọc hết toàn bộ nội dung:
Page ID: Định danh duy nhất của trang trong toàn bộ file cơ sở dữ liệu.
Free Space Pointer: Con trỏ đánh dấu vị trí trống tiếp theo để ghi dữ liệu. Nó giúp DBMS biết ngay lập tức Page còn bao nhiêu chỗ mà không cần quét lại từ đầu.
Slot Count: Tổng số lượng bản ghi đang hiện hữu (bao gồm cả các bản ghi đã bị đánh dấu xóa).
Magic Number/Checksum: Dùng để kiểm tra tính toàn vẹn của dữ liệu, đảm bảo Page không bị hỏng (corrupted) trong quá trình ghi xuống đĩa.
2.2. Slot Array: Tấm bản đồ nội bộ (Mọc từ trên xuống)
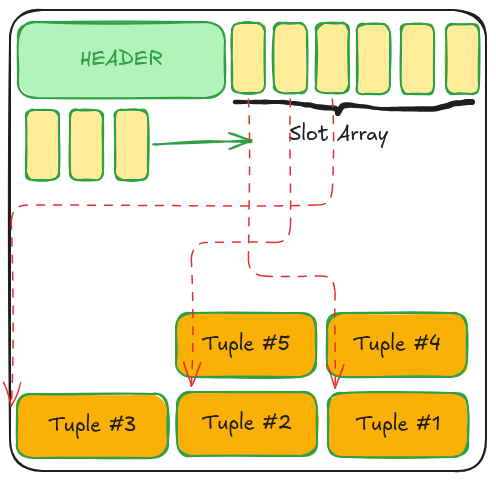 Đây chính là "trái tim" của Slotted Page Layout. Slot Array là một mảng các ô nhớ có kích thước cố định (thường là 2-4 byte cho mỗi ô).
Đây chính là "trái tim" của Slotted Page Layout. Slot Array là một mảng các ô nhớ có kích thước cố định (thường là 2-4 byte cho mỗi ô).
Cơ chế: Khi một dòng dữ liệu mới được thêm vào, một "khe" (slot) mới sẽ được tạo ra trong mảng này.
Nội dung: Mỗi ô trong Slot Array không chứa dữ liệu, nó chỉ chứa Offset (khoảng cách tính từ đầu Page) trỏ đến vị trí bắt đầu của dòng dữ liệu thực tế ở phía dưới.
Hướng phát triển: Mảng này sẽ lớn dần từ phía Header đi xuống dưới tâm của Page.
2.3. Dữ liệu thực tế (Tuples/Rows - Mọc từ dưới lên)
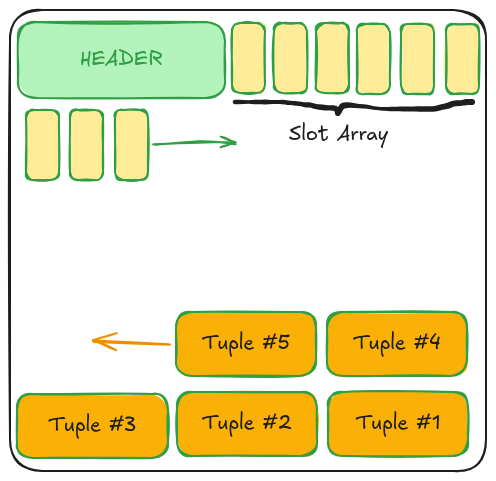 Khác với mảng Slot, dữ liệu thực tế được ghi từ cuối Page ngược lên trên.
Khác với mảng Slot, dữ liệu thực tế được ghi từ cuối Page ngược lên trên.
Mỗi khi có
INSERT, DBMS sẽ tính toán vị trí trống ở đáy Page, đặt dữ liệu vào đó, rồi quay lại cập nhật vị trí vào Slot Array.Tại sao lại mọc ngược chiều? Thiết kế này cực kỳ tinh tế vì nó cho phép Slot Array (có kích thước biến thiên theo số bản ghi) và Dữ liệu (có kích thước biến thiên tùy độ dài dòng) tận dụng chung một khoảng trống ở giữa (Free Space) mà không bao giờ dẫm chân lên nhau cho đến khi Page thực sự đầy.
2.4. Khoảng trống linh hoạt (Free Space)
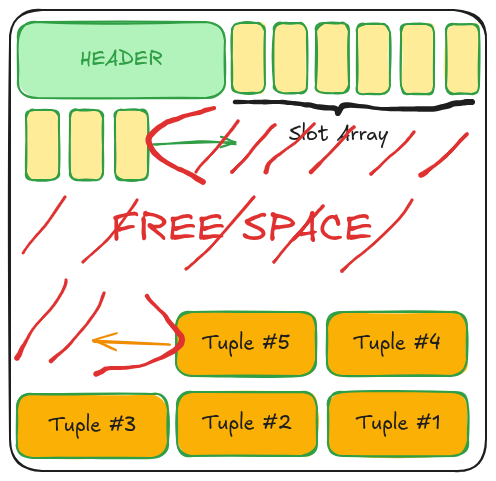 "Hình 1: Cấu trúc Slotted Page – Slot Array mọc từ trên xuống, Tuple mọc từ dưới lên"
"Hình 1: Cấu trúc Slotted Page – Slot Array mọc từ trên xuống, Tuple mọc từ dưới lên"
Khoảng trống ở giữa Page chính là nơi diễn ra các hoạt động "dồn dịch" dữ liệu. Khi bạn xóa một bản ghi ở giữa, DBMS chỉ đơn giản là đánh dấu khe đó là trống. Khi Page cần thêm không gian, DBMS có thể thực hiện Defragmentation (chống phân mảnh): nó dồn toàn bộ các dòng dữ liệu sát lại với nhau để tạo ra một khối trống liên tục ở giữa mà không làm thay đổi các số thứ tự trong Slot Array.
3. RID (Record ID) – Địa chỉ "hộ khẩu" vĩnh viễn
Sau khi đã hiểu Slot Array và Tuple Data mọc ngược chiều nhau, chúng ta sẽ chạm đến khái niệm quan trọng nhất: RID.
Trong Database, mỗi dòng dữ liệu không được gọi tên bằng ID (như Primary Key) mà được định danh bằng một địa chỉ vật lý gọi là RID (Record Identifier). RID thường là một cặp giá trị: [Page_ID, Slot_Number].
Tại sao RID lại được coi là "bất biến"? Hãy nhìn vào hình minh họa ở trên. Giả sử bạn có một bản ghi nằm ở Slot 5:
Nếu bạn xóa bản ghi ở
Slot 4, vùng dữ liệu (Tuple) củaSlot 5có thể được Database dồn dịch lên phía trên để lấp chỗ trống (Defragmentation).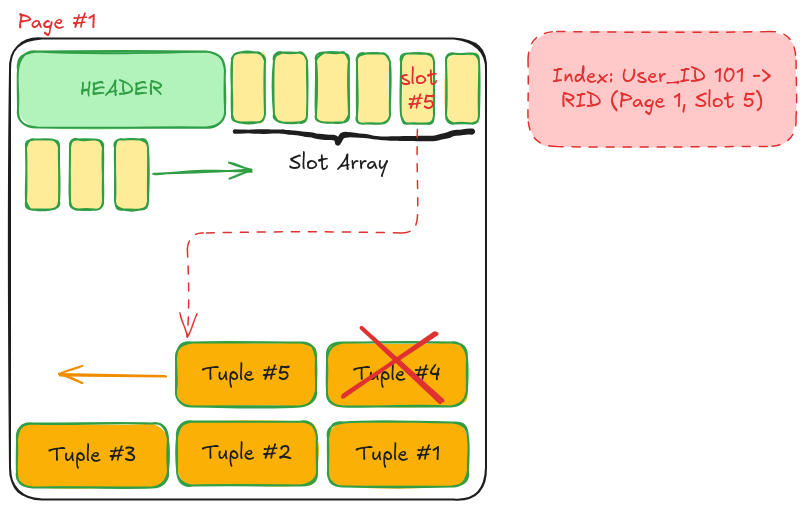 Tuy nhiên, dù dữ liệu thực tế có bị dịch chuyển đi đâu trong Page, thì ô Slot 5 ở phía Header vẫn nằm im tại đó và chỉ cần cập nhật lại con trỏ (Offset) mới.
Tuy nhiên, dù dữ liệu thực tế có bị dịch chuyển đi đâu trong Page, thì ô Slot 5 ở phía Header vẫn nằm im tại đó và chỉ cần cập nhật lại con trỏ (Offset) mới.
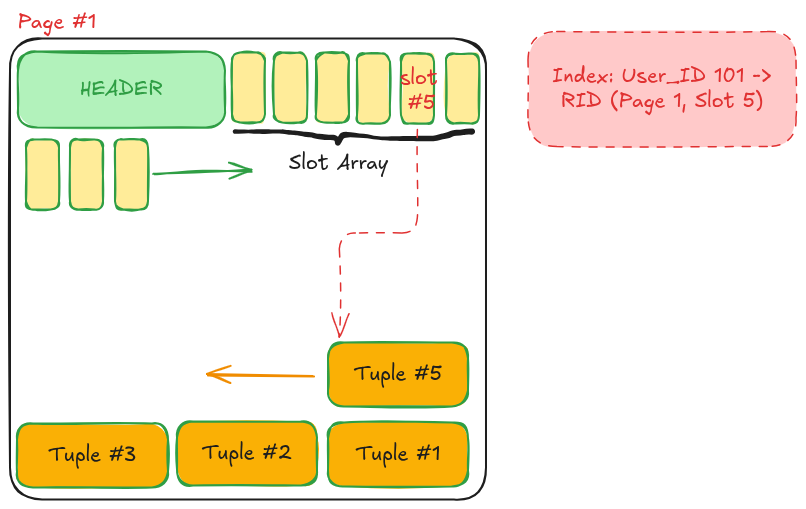
Kết quả: Đối với thế giới bên ngoài (như các Index), bản ghi đó vẫn nằm ở Slot 5.
Tại sao điều này lại quan trọng?
Index bền bỉ: Các bộ chỉ mục (Index) như B-Tree chỉ cần lưu RID. Vì RID không đổi, Database không cần phải tốn công cập nhật lại hàng triệu Index mỗi khi dữ liệu bên trong Page bị xắp xếp lại.
Tốc độ truy xuất: Chỉ cần có RID, DBMS sẽ nhảy thẳng đến đúng Page, nhìn vào Slot và lấy ngay được dữ liệu mà không cần quét (scan) bất cứ thứ gì.
4. Cơ chế Xóa: Tại sao file Database không bao giờ nhỏ lại?
Trong Slotted Page, khi bạn thực hiện lệnh DELETE, Database không thực sự xóa sạch dữ liệu đó trên đĩa cứng ngay lập tức. Thay vào đó, nó sử dụng cơ chế Tombstone (Đánh dấu xóa):
Tombstone Bit: DBMS chỉ đơn giản là đánh dấu 1 bit trong Header của Slot đó là "đã xóa".
Reusable Space: Khoảng trống cũ vẫn nằm đó. Lần tới khi bạn
INSERTmột bản ghi mới có kích thước tương đương hoặc nhỏ hơn, DBMS sẽ ưu tiên tái sử dụng (reuse) chính cái Slot này.Hệ quả: Đây là lý do tại sao bạn xóa hàng triệu dòng dữ liệu nhưng dung lượng file
.dbtrên đĩa vẫn không giảm đi. Bạn cần các lệnh đặc biệt nhưVACUUM FULL(Postgres) hayOPTIMIZE TABLE(MySQL) để thực sự dồn dịch dữ liệu và trả lại không gian cho hệ điều hành.
5. Cập nhật và hiện tượng "Bục trang" (Page Overflow)
Chuyện gì xảy ra nếu bạn cập nhật một cột VARCHAR từ 10 ký tự lên 1000 ký tự, và cái Page đó không còn đủ chỗ trống?
Row Fragmenting (Phân mảnh dòng): Database sẽ phải cắt bản ghi đó ra. Phần đầu vẫn nằm ở Page cũ, nhưng nó sẽ chứa một Forwarding Pointer (con trỏ chuyển tiếp) trỏ đến một Page mới hoàn toàn nơi phần còn lại của dữ liệu đang nằm.
Cái giá về hiệu năng: Lúc này, thay vì chỉ cần 1 lần Disk I/O để đọc 1 Page, ông thủ thư phải thực hiện 2 hoặc nhiều lần "đi bộ" để lấy đủ một dòng dữ liệu. Đây chính là nguyên nhân khiến các câu lệnh
UPDATEđôi khi chậm kinh khủng nếu thiết kế data model không tốt.
6. Sự phối hợp với tầng Buffer Pool Manager
Dựa trên sơ đồ kiến trúc bạn đã có, Slotted Page không hoạt động cô lập:
Dirty Pages: Khi bạn sửa đổi dữ liệu trong một Page trên RAM, Page đó được đánh dấu là "Dirty".
Flush to Disk: Tầng Buffer Pool Manager sẽ không ghi ngay xuống đĩa (vì rất chậm). Nó sẽ đợi đến một thời điểm thích hợp (Checkpointed) để ghi hàng loạt các Dirty Pages xuống Disk Manager cùng một lúc. Điều này giúp tối ưu hóa băng thông ghi của ổ cứng.


![[Series] Database Internals - Bài 1: Tại sao RDBMS lưu dữ liệu khác với File thông thường?](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.5746714924169717.png&w=3840&q=75)