Tại sao B-Tree lại là "Vua" của Index trong Database?
Nếu bạn từng thắc mắc tại sao khi tạo một Index, tốc độ truy vấn
SELECTlại nhanh lên hàng trăm lần, thì câu trả lời nằm ở một cấu trúc dữ liệu mang tên B-Tree. Tuy nhiên, tại sao không phải là BST (Binary Search Tree) — thứ mà chúng ta đều được học ở trường?Hãy cùng "mổ xẻ" những bí mật bên trong bộ máy lưu trữ của Database.
1. Cuộc chiến giữa RAM và Disk: Kẻ thù của tốc độ
Lý do đầu tiên không nằm ở thuật toán, mà nằm ở phần cứng.
RAM: Tốc độ cực nhanh nhưng đắt và dữ liệu mất đi khi mất điện.
Disk (HDD/SSD): Dung lượng lớn, rẻ, nhưng tốc độ truy cập chậm hơn RAM hàng ngàn lần.
Các cấu trúc dữ liệu như BST được thiết kế để sống trên RAM. Trên RAM, việc nhảy từ node này sang node kia (con trỏ) gần như tức thời. Nhưng trên Disk, mỗi lần bạn "nhảy" như vậy, Database phải thực hiện một thao tác I/O.Sự thật là: Thao tác I/O trên đĩa là rào cản lớn nhất đối với hiệu năng Database. Mục tiêu tối thượng của một Index là: Tìm thấy dữ liệu với ít lần đọc đĩa (I/O) nhất có thể.
2. Tại sao BST (Binary Search Tree) thất bại trên Disk?
Giả sử bạn có 1 triệu bản ghi.
Với BST, chiều cao của cây (height) sẽ xấp xỉ $\log_2(1,000,000) \approx 20$.
Điều này có nghĩa là để tìm một bản ghi, bạn có thể phải thực hiện 20 lần đọc đĩa khác nhau.
Nếu các node của BST nằm rải rác trên đĩa, mỗi lần di chuyển là một lần Random I/O (đầu đọc phải di chuyển vật lý đến vị trí mới). Điều này cực kỳ chậm. Hơn nữa, nếu cây bị mất cân bằng (ví dụ: các node chỉ trỏ về một phía 1-2-3-4), độ phức tạp sẽ tệ đi thành $O(n)$, biến cây thành một danh sách liên kết "vô dụng"
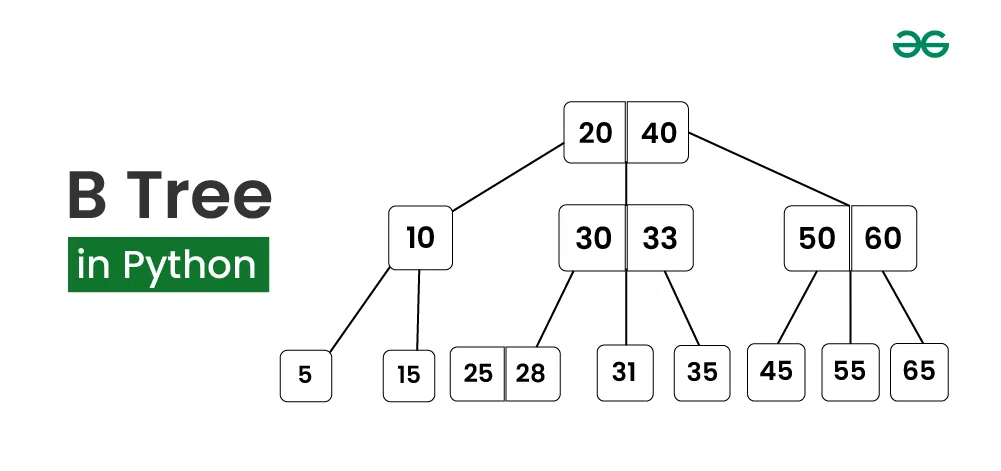
3. B-Tree: Giải pháp "Lùn nhưng Rộng"
B-Tree giải quyết vấn đề của BST bằng hai chiến thuật: High Fanout (nhiều con trên một node) và Low Height (chiều cao thấp).
Khái niệm Disk Page (Trang đĩa)
Trong nội tại Database, dữ liệu không được đọc theo từng byte. Mỗi node của B-Tree thường được thiết kế để khớp vừa vặn với một Disk Page (thường là 4KB, 8KB hoặc 16KB).
Thay vì chỉ chứa 1 giá trị và 2 con trỏ như BST, một node của B-Tree có thể chứa hàng trăm giá trị và hàng trăm con trỏ tới các node con.
Sức mạnh của sự cân bằng
High Fanout: Một node có "fanout" là 100 nghĩa là nó có 100 con. Với chỉ 3 tầng, bạn có thể lưu trữ $100^3 = 1,000,000$ bản ghi.
Số lần I/O: Thay vì 20 lần như BST, bạn chỉ cần 3 lần đọc đĩa để tìm thấy dữ liệu.
Tự cân bằng: B-Tree luôn đảm bảo các lá ở cùng một độ sâu. Nếu một nhánh quá nặng, cây sẽ tự thực hiện "rebuild" (ví dụ: chuyển node 2 lên làm gốc thay vì 1-2-3) để giữ độ cao thấp nhất có thể.
4. So sánh nhanh: BST vs. B-Tree
Đặc điểm | Binary Search Tree (BST) | B-Tree |
Môi trường tối ưu | RAM (Bộ nhớ trong) | Disk (Ổ cứng) |
Số con mỗi node | Tối đa 2 | Rất nhiều (High Fanout) |
Chiều cao cây | Rất cao | Rất thấp (Flat) |
Số lần I/O đĩa | Nhiều (Tệ cho hiệu năng) | Rất ít (Tối ưu I/O) |
Ứng dụng | Thuật toán tìm kiếm cơ bản | Index trong MySQL, PostgreSQL, Oracle |
5. Mở rộng: Khi B-Tree gặp đối thủ LSM Tree
Dù B-Tree là "vua" đọc dữ liệu, nó lại có một điểm yếu: Write Performance. Khi bạn cập nhật dữ liệu, B-Tree phải tìm vị trí chính xác trên đĩa để ghi (Random I/O), điều này gây tốn kém.
Đây là lúc các NoSQL database (như Cassandra, LevelDB) xuất hiện với LSM Tree (Log-Structured Merge-Tree).
LSM Tree không ghi trực tiếp vào cây. Nó ghi tuần tự vào một file log (Sequential I/O - cực nhanh).
Sau đó, nó mới gộp (merge) các file này lại sau.
Kết luận: Nếu hệ thống của bạn cần Ghi (Write) cực nhiều, LSM Tree là lựa chọn tốt hơn B-Tree.
Lời kết
B-Tree không chỉ là một cấu trúc dữ liệu, nó là một thiết kế thông minh dựa trên sự hiểu biết sâu sắc về phần cứng máy tính. Việc hiểu rõ cách B-Tree hoạt động sẽ giúp bạn biết cách đánh Index sao cho đúng, tránh việc lạm dụng Index khiến tốc độ ghi bị trì trệ.


![[Series] Database Internals - Bài 1: Tại sao RDBMS lưu dữ liệu khác với File thông thường?](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.5746714924169717.png&w=3840&q=75)
![[Series] Database Internals - Bài 2: Giải mã "Thùng sách" – Nghệ thuật sắp xếp Slotted Page Layout](/_next/image?url=https%3A%2F%2Fnllgiwbecqskpipvcvpt.supabase.co%2Fstorage%2Fv1%2Fobject%2Fpublic%2Fblog-images%2F0.30555181914624063.png&w=3840&q=75)